Over the past few years, Large Language Models (LLMs) like ChatGPT, Claude, and LLaMA have taken centre stage in AI research and product development. These models are incredibly powerful at generating human-like text, answering questions, summarising content, and more.
But now, a new paradigm is emerging: AI Agents. These are not just models that predict text—they are systems that act. They plan, use tools, interact with environments, and complete tasks autonomously.
So, what exactly is the difference between an LLM and an AI Agent? How do they work under the hood? And when should you use one over the other?
In this blog we will see how agents are different from LLMs not just theoretically but mathematically with some intuitive examples and simple mathematics.
To explain how agents differ from LLMs, we’ll need to break it down into two parts:
LLMs:
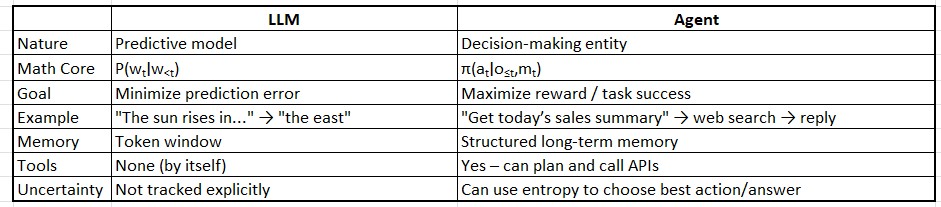
An LLM is a function approximator: it maps a sequence of tokens (words) to the next token, using probabilities.
Mathematical Definition:
An LLM approximates the probability distribution:
P(wt∣w1,w2,…,wt−1;θ) ,where:
-wt: next token
-w1,…,wt−1: context tokens
-θ: model parameters (weights of neural net)
LLMs are trained to minimize cross-entropy loss:
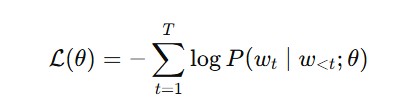
The LLM is a pure function, like:
LLM: Input Text→ Next Token Distribution
Agents: Decision-Making with Goals + Memory + Tools
An agent is a broader computational entity that can:
- Perceive its environment (via observations),
- Decide on actions,
- Execute those actions,
- Update memory,
- Often uses LLMs as tools.
Mathematical Definition
An agent’s behaviour can be modelled as a policy function in a Partially Observable Markov Decision Process (POMDP): π(at∣o≤t,mt)
- at: action at time t
- o≤t: sequence of observations up to time t
- mt: internal memory or belief state
Agent’s objective: Maximize expected reward:
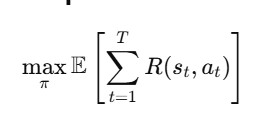
where:
- st: hidden state (environment)
- R(st,at): reward function
Example:
Let’s take an example .
“The sun rises in the ….”
We’ll explain mathematically and intuitively what:
- An LLM does
- An Agent does (which may use an LLM)
LLM Behavior — Predicting Next Token
P(wt=‘east’∣ w1=‘The’, w2=‘sun’, w3=‘rises’, w4=‘in’, w5=‘the’; θ)
Where:
-wt: next word
-w<t: previous words
-θ: model parameters (weights from training)
It estimates probabilities of possible next tokens:
| Tokens | Probability |
|---|---|
| east | 0.92 |
| morning | 0.03 |
| sky | 0.02 |
| west | 0.01 |
| north | 0.01 |
As it is evident from the table “east” has the highest probability(0.92)
So LLM completes:
“The sun rises in the east“
LLM doesn’t verify if it’s true — it just chooses the most statistically likely word based on training.
Now let’s see how an Agent reacts to the same input.
Agent’s behaviour (policy):
π(at ∣o≤t, mt)
Where:
-at: action (e.g., “search”, “ask LLM”, “query KB”)
-o≤t: all observations (input, environment)
-mt: memory (state, facts)
Steps an Agent might take:
- Observation: “The sun rises in the …”
- Recognize task: This is a factual statement; needs knowledge.
- Action: Query tool or LLM for fact:
- Use a tool: a1=call_knowledge_base(“sunrise direction”)
- → returns
"east"
- Form answer: “The sun rises in the east.”
Deep dive into Agent’s inner working
Let’s go deep into the math behind how an Agent processes:
“The sun rises in the …”
We’ll model this using POMDP (Partially Observable Markov Decision Process) framework — the foundation for goal-driven agents — and show how it differs from a stateless LLM
Agent Framework (POMDP View):
An agent operates over time using a policy:
π(at ∣o≤t, mt)
where:
-at: action (e.g., “search”, “ask LLM”, “query Knowledge Base”)
-o≤t: all observations (input, environment)
-mt: memory (state, facts)
Agent’s goal :
maximize total expected reward:
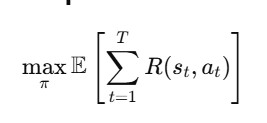
Where:
st: true (hidden) environment state at time t
R(st,at): reward received after action
Now steps taken by the agent for :
“The sun rises in the ….”
Step 1: Observation ot
Agent reads user prompt: ot=“The sun rises in the …”
This is partially observable — it doesn’t fully tell us what the user wants (completion? verification? correction?). So the agent must infer intent.
Step 2: Belief/Memory State (mt)
Assume agent has a belief or internal memory, such as:
mt={facts: sunrise: “east”,
user intents: [“complete”, “fact-check”]}
This belief state helps the agent remember important information. It typically contains:
Facts:
Knowledge the agent has acquired or been told.
Example: "sunrise": "east" → the agent knows the sun rises in the east.
User Intents:
What the user has asked or wants to do.
Example: ["complete", "fact-check"] → the user wants the agent to complete a task and also verify some facts.
Purpose:
This structured memory helps the agent make decisions more intelligently — by combining current observations with what it already knows or assumes.
Step 3: Inference
The agent needs to estimate what state the user wants completed:
Let:
- st: Hidden user intent (e.g. “complete sentence”, “verify fact”)
Agent maintains a belief distribution over states:
bt(st)=P(at ∣o≤t, m)
Let’s assume:
| State (user intent) | Probability |
|---|---|
| complete sentence | 0.80 |
| ask for fact | 0.15 |
| irrelevant | 0.05 |
Step 4: Action Selection
Agent uses policy “π” to select the next action:
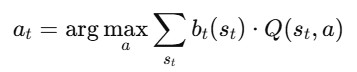
Where:
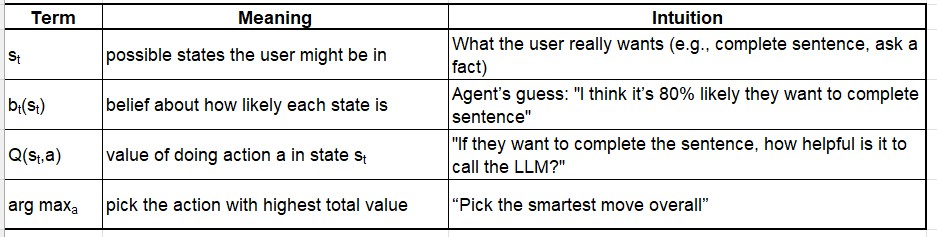
Q(st,a): estimated value of taking action ‘a’ in state ‘st‘
[Choose the action ‘a’ that has the highest expected value, based on your beliefs bt(st) about the current situation, and your estimate of how good each action is in each situation Q(st,a)]
Let’s now break down each part:
“The sun rises in the …”
The agent isn’t 100% sure what the user wants. It considers two possible intentions (states):
| State st | Meaning | Belief bt(st) |
|---|---|---|
complete | User wants to complete the sentence | 0.80 (80% likely) |
verify | User wants to fact-check a statement | 0.20 (20% likely) |
Now the agent thinks:
“Which action should I take?”
Candidate Actions:
| Action | Description |
|---|---|
LLM_Complete() | Use LLM to complete the sentence |
lookup("sunrise") | Check a tool/knowledge base |
ask_clarification() | Ask user: “Do you want to complete or fact-check?” |
The Agent’s Knowledge: Q-values
Q-values are like ratings of how good each action is in each situation.
Let’s say:
| State | Action | Q(st,a) |
|---|---|---|
| complete | LLM_Complete | 0.8 |
| complete | lookup | 0.9 |
| verify | LLM_Complete | 0.5 |
| verify | lookup | 0.95 |
Expected Value of Each Action:
Now compute the expected value of each action across both possible states:
For LLM_Complete:
EV=0.8⋅0.8+0.2⋅0.5=0.64+0.10=0.74
For lookup("sunrise"):
EV=0.8⋅0.9+0.2⋅0.95=0.72+0.19=0.91
For ask_clarification (say we assign 0.5 in both cases):
EV=0.8×0.5+0.2×0.5=0.4+0.1=0.5
Agent chooses:
at= arg maxa EV(a)=lookup(“sunrise”)
Because it gives the highest expected benefit, given uncertainty.
Step 5: Execute Action → Get Result
result=tool(“sunrise”)=”east”
Now agent updates memory: mt+1=mt∪{completion: “east”}
Step 6: Generate Output
Use template or LLM to form:
“The sun rises in the east“
Conclusion:
TL;DR
0 Comments