With the rise and rise of generative AI in the Tech world , one can’t stay unaware of the Large Language Models(LLMs).These cutting age models are known to do human like tasks, behave like humans and respond like humans when asked questions.With each passing day they are growing in size and improving their performance.
Here size predominantly refers to the number of parameters or weights.Very often when we come across a LLM , it is usually perceived in terms of number of parameters.More the parameters , bigger the LLM is.Number of parameters could range from couple millions to some billions.
Example:
BERT-340 million
GPT 2-1.5 billion
GPT 3-175 billion
Bloom -175 billion
Palm2- 340 billion
With such huge number of parameters and thus huge size, it usually requires huge memory space and multiple GPUs to run these LLMs which is very expensive and not easily accesible to everyone.
But researchers have come up with one technique called “Quantization” to deal with such problems. Applying quantization it is possible to reduce the memory requirements of an LLM and thereby enabling the user to run it in a lower resource environment.
Quantization:
Quantization is the process of representing weights, bias and activations in neural networks using lower-precision data types, such as 8-bit integers (int8), instead of the conventional 32-bit floating point (float32) representation. By doing so, it significantly reduces the memory footprint and computational demands during inference, enabling deployment on resource-constrained devices.
In this article we will see how to load a huge LLM(“Bloom” with 3 billion parameters)
in Google’s colab with a single GPU.
###Install bits and bytes library to support quantization of models
!pip install --quiet bitsandbytes
!pip install --quiet git+https://github.com/huggingface/transformers.git # Install latest #version of transformers
!pip install --quiet accelerate###Check GPU status
###Change the runtime to GPU in Colab
gpu_info = !nvidia-smi
gpu_info = '\n'.join(gpu_info)
if gpu_info.find('failed') >= 0:
print('Not connected to a GPU')
else:
print(gpu_info)##Load the original 3 billion model
name = "bigscience/bloom-3b"
max_new_tokens = 20
def generate_from_model(model, tokenizer):
encoded_input = tokenizer(text, return_tensors='pt')
output_sequences = model.generate(input_ids=encoded_input['input_ids'].cuda())
return tokenizer.decode(output_sequences[0], skip_special_tokens=True)
from transformers import pipeline
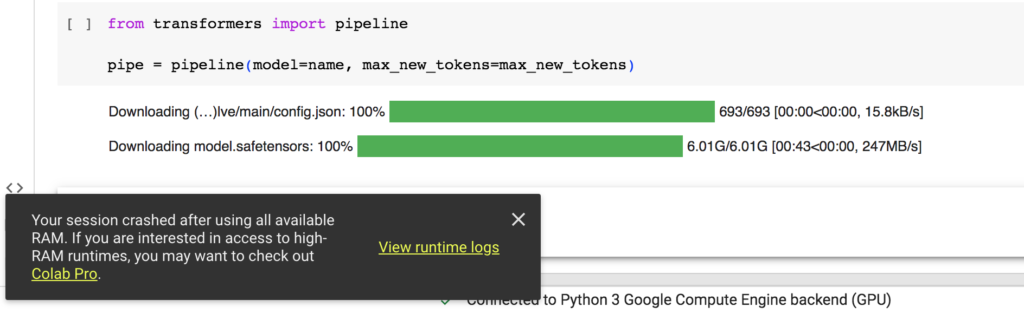
pipe = pipeline(model=name, max_new_tokens=max_new_tokens)Here is the output:
It can be seen that Colab crashed due to insufficient memory owing to the huge size and large number of parameters(3 billion)
Now let’s try to load the quantized 8-bit integer model.This can be done by setting the “load_in_8bit” to True as shown in the below code.
from transformers import pipeline
pipe = pipeline(model=name, model_kwargs= {"device_map": "auto", "load_in_8bit": True}, max_new_tokens=max_new_tokens)
Here is the output.Voila! The model has been loaded.
Testing the quantized model
Now Let’s try to test the quantized model.We will give it a random text string and ask it to generate few words.
text="AI can do multiple tasks such as"
pipe(text)Output:

The quantised model successfully generated some text based on the text given to it(“AI can do multiple tasks such as”)
Here we have used transformer pipeline method to generate the text after loading the model.
The same can be done using the previously defined function “generate_from_model”.
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
model_8bit = AutoModelForCausalLM.from_pretrained(name, device_map="auto", load_in_8bit=True)
tokenizer = AutoTokenizer.from_pretrained(name)
generate_from_model(model_8bit, tokenizer)Output:

That’s all for this article.
Conclusion:
We saw how to load a huge LLM using the quantization method.Try to load other models and longer sequences to check the response of the model.
0 Comments